Table of Contents
Every second matters in modern data-centric applications. Whether you are running an e-commerce application, a banking system, or a SaaS application built through custom software development services, slow database query performance reduces user experience and inflates infrastructure costs.
Query optimization in database systems is the engineering discipline that separates a slow system from a system that responds in milliseconds or less. As data sets continue to scale into the hundreds of gigabytes or even the terabyte range, even the best-designed applications developed through web application development services can fail due to suboptimally written SQL code.
A database query performance that took 200ms on 1 million rows can take 45 seconds on 100 million rows, not because the system has failed, but because the query execution strategy was never revisited or optimized. This guide offers 15 tested and actionable techniques for query optimization in database systems.
Whether you are in the business of running PostgreSQL, MySQL, Microsoft SQL Server, or any distributed database system, these techniques for query optimization in database systems help you reduce query latency, CPU utilization, and memory pressure, and deliver systems of SQL query optimization that scale.
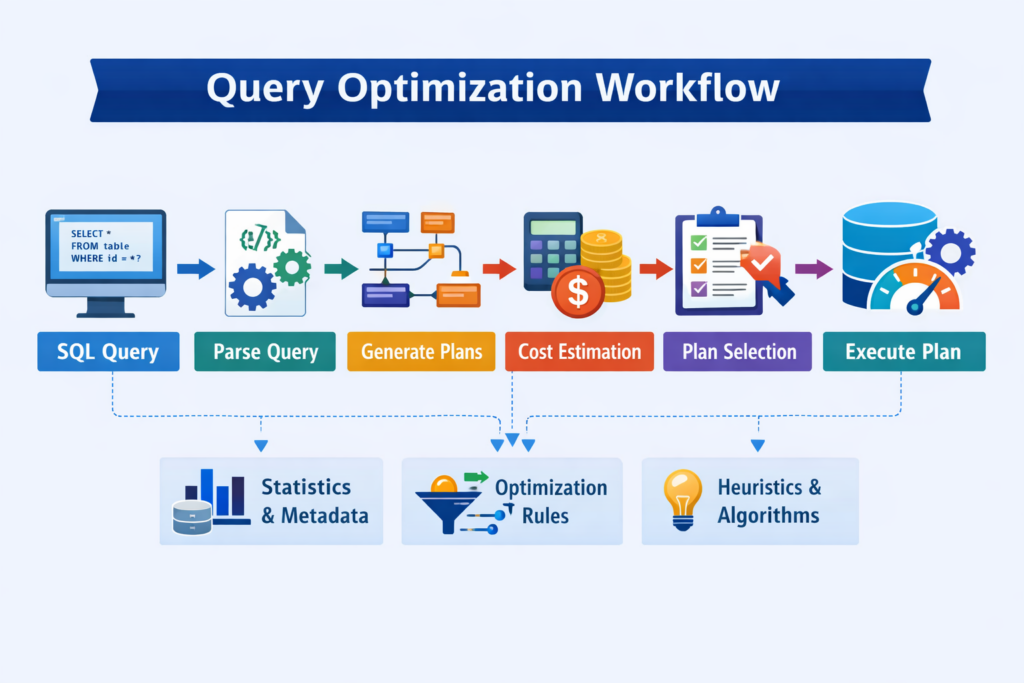
The query optimization in database systems is the way by which the database system or the developer examines the various ways of executing the query and selects the one that takes the least amount of time and resources to execute the query.
In modern applications, this directly impacts user experience. According to research by Google, 53% of users abandon a site if it takes more than 3 seconds to load, making efficient query performance critical for retention.
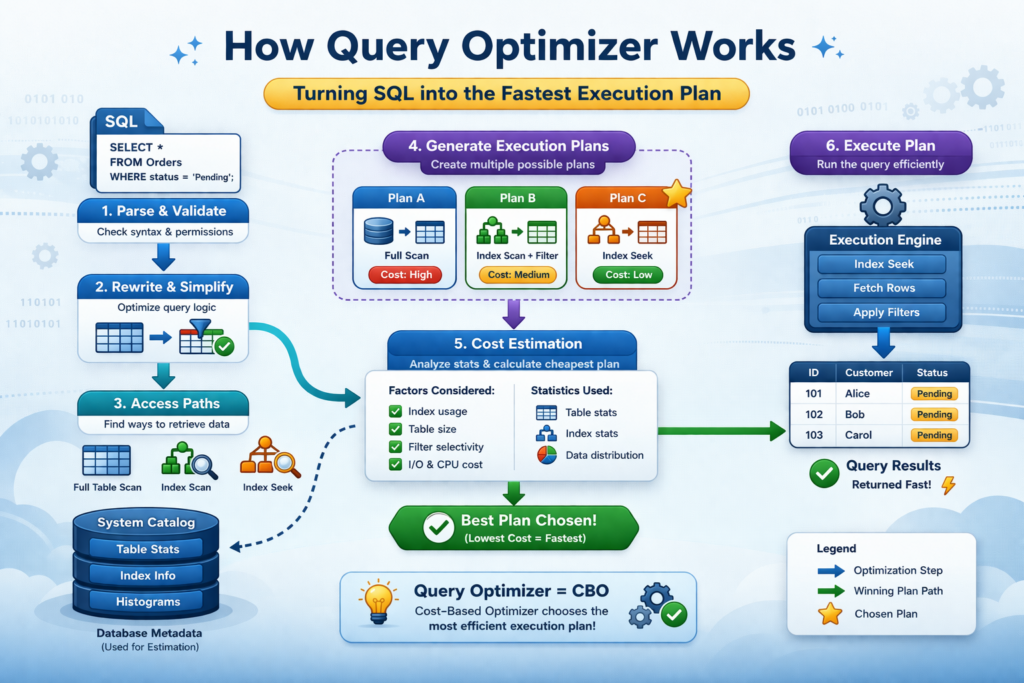
It is the role of the query optimization in database systems to act as an intelligent query planner by reading the query you wrote, examining the indexes available, and estimating the number of records each operation will be performing. The Execution plan efficiency is the way by which the query optimization is measured.
The cost-based query optimization in database systems is the one used by modern relational databases like PostgreSQL and SQL Server to optimize dynamic query execution by assigning a cost to each execution plan and choosing the one with the lowest cost. If the query is not written properly, the SQL query optimization may get confused and select the suboptimal execution plan.
Understanding how this works can help us to guide it, which is the core of database performance tuning. If the execution plan efficiency is low, then the query or schema mismatch is the cause of the database query performance.
Slow database query performance and operations worsen the situation beyond slow page loading. Every development team that fails to consider query optimization in database systems will face impacts:
User experience suffers: Users get frustrated with pages taking more than 3 seconds to load. An unoptimized query can cause the connection to hang for minutes.
Resource costs escalate: Resources like CPU, memory, and I/O operations are directly proportional to query performance.
Scalability fails: An unoptimized query in database systems that was fine with small data can fail with large data.
Lock contention worsens: Long-running queries can cause transactions to wait and cascade the slow performance.
Query optimization in database systems is a continuous process that helps maintain database query performance and achieve scaling.
Adaptive indexing strategies are the best optimization strategy in query optimization in database systems. Clustered indexes are the physical ordering of rows based on the key values of SQL query optimization. Non-clustered indexes on filtered columns are used for direct lookups.
Full-text indexes are faster than LIKE '%keyword%'. Adaptive learned indexes adjust to patterns in the workload. A composite index on (status, order_date) reduced the query execution from 8.2s to 0.04s.
Cost based optimization (CBO) selects the cheapest execution plan efficiency supported by PostgreSQL, Oracle, and SQL Server for query optimization in database systems. Statistics need to be maintained using ANALYZE or UPDATE STATISTICS. Heuristic query optimization is the use of rules that are always true, regardless of the data.
Executing the execution plan is the most critical step in query optimization in database systems. PostgreSQL: EXPLAIN ANALYZE (as detailed in the PostgreSQL EXPLAIN documentation). MySQL: EXPLAIN. SQL Server: SET STATISTICS IO ON. Look for sequential scans (poor execution plan efficiency) and actual vs. estimated row mismatches of SQL query optimization. After using ANALYZE on the table with 10M rows, database query performance execution decreased from 12s to 0.3s.
Joining multiple tables excessively can cause an enormous number of intermediate results of query optimization in database systems. Always filter the largest table first when using join performance techniques for execution plan efficiency.
Always only join indexed columns, as un-indexed table keys will take a large amount of time to run a full inner scan for each outer row. INNER JOIN will generally be quicker than LEFT JOINs, as they will block any optimizations being used.
Filtering data early to shrink every downstream operation in Database query performance. Avoid functions on indexed columns: WHERE YEAR(order_date) = 2024 disables the index.
Use a BETWEEN range in query optimization in database systems. Avoid implicit type conversions. Apply the most selective filter first in SQL query optimization. Rewriting WHERE SUBSTRING(email,1,5) = 'admin' to WHERE email LIKE 'admin%' cut a 4s query to 0.1s.
Reduce Full table scans, which read every row from disk, a core target in query optimization in database systems. Fix by: adding indexes, refreshing statistics, replacing LIKE '%keyword%' with full-text search, and query rewriting OR conditions as UNION. Monitor pg_stat_user_tables (PostgreSQL) or sys.dm_exec_query_stats (SQL Server).
Break long queries into smaller pieces in query optimization in database systems. CTEs isolate subsets early for execution plan efficiency. Temp tables allow targeted indexes on intermediate results. Staged processing lets each step be profiled for database query performance. A 12-table reconciliation query refactored into 4 CTEs dropped from 47 minutes to 3 minutes.
Materialized views pre-compute and store expensive query results, underused in query optimization in database systems. Best for large aggregations, repeated joins, distributed database optimization, and BI dashboards.
Use REFRESH MATERIALIZED VIEW CONCURRENTLY (PostgreSQL) to avoid blocking readers. They power parallel query processing in Redshift, Snowflake, and BigQuery.
In systems relying on multiple integrations, especially those built with API integration services, query caching avoids redundant re-execution… without changing SQL query optimization. Cache results in Redis or Memcached with TTLs and write-invalidation logic. Prepared statements eliminate reprocessing plan caching built into query optimization in database systems. PgBouncer and ProxySQL cache plans at the connection layer.
Use EXISTS over IN; EXISTS stops at the first match; IN builds a full result set in subquery optimization in database systems. On 5M rows, this cut query time from 9.4s to 0.8s. Replace correlated subqueries with JOINs: a per-row MAX subquery runs millions of times; a JOIN with GROUP BY runs once. NOT EXISTS is safer and faster than NOT IN.
Always specify columns. SELECT * wastes I/O, memory, and bandwidth. Add LIMIT on every paginated query. Use keyset pagination: WHERE id > last_id LIMIT 20 is O(1); OFFSET 100000 scans 100K rows first. Aggregate in the database, not application code for Query optimization in database systems.
In distributed environments powered by scalable cloud services, parallel query processing splits large scans across CPU cores for execution plan efficiency. PostgreSQL auto-parallelizes scans, hash joins, and aggregations configure max_parallel_workers_per_gather.
SQL Server applies parallel plans above the cost threshold. Spark SQL, Redshift, and BigQuery (using techniques outlined in BigQuery query optimization best practices) execute query optimization in database systems across distributed nodes.
A schema is the foundation of query optimization in database systems. Normalize OLTP schemas. Denormalize analytics schemas to reduce join depth. Use INT over VARCHAR for IDs; DATE for dates. Partition large tables by date for partition pruning. Every serious database performance tuning engagement starts: Does this schema serve the workload?
Query optimization in database systems without monitoring is guesswork. pg_stat_statements (PostgreSQL) identifies expensive queries by mean time. MySQL slow_query_log + pt-query-digest ranks them. SQL Server Query Store catches plan regressions. Datadog, New Relic, and Dynatrace trace latency from application to Database query performance. Review weekly; audit quarterly for SQL query optimization.
AI is the frontier of query optimization in database systems. Learned cardinality estimation (Neo, Bao from MIT, as explored in machine learning based query optimization research) delivers 2–3x speedups. Spark SQL's Adaptive Query Execution adjusts join strategies mid-query. Microsoft AutoIndex creates and drops indexes based on workload. Machine learning in query optimization achieves what manual SQL query optimization cannot at an enterprise scale for execution plan efficiency.
However, Query optimization in database systems looks different for every system. It requires expertise in your schema, your workload patterns, and your database engine. Exactly this expertise is offered by Patoliya Infotech.
We have practical experience with query optimization in database systems using various database management systems, such as PostgreSQL, MySQL, MS SQL Server, Oracle, Redshift, and BigQuery. Every query optimization in database systems is a focused exercise that yields tangible results.
We provide execution plan deep dives that yield direct improvements to database performance tuning. We review your indexing architecture to eliminate unnecessary indexes that cause write slowdowns, as well as add precision indexes that enable faster reads. We optimize your schema and SQL queries. We also apply ML based query optimization techniques that enable adaptive cost models in large-scale database systems.
We help our customers achieve significantly faster query execution times. If query execution is slowing your business, it may be time to evaluate how you can optimize your database performance with the right engineering approach.
Query optimization in database systems is not an optional activity for database systems. Unoptimized queries will damage user trust, increase costs, and hinder business growth through Database query performance.
These 15 methods, from indexing and execution plan analysis to SQL query optimization best practices, provide you with a comprehensive list of tools. Before you start, profiling should be used to determine your slowest-running queries. The systems that scale are the ones where query optimization in database systems is an ongoing engineering discipline.